Download UNIT 3 COMPILER DESIGN and more Study notes Compiler Design in PDF only on Docsity!
UNIT 3 SYNTAX ANALYSIS – PARSING 10
Syntax Analysis: Role of the parser - Context free grammars - Top-down parsing: shift reduce
- predictive parsing; Bottom-up parsing: Operator precedence, LR parsers (SLR, Canonical LR,LALR) - Parser generators-Design aspects of Parser.
SYNTAX ANALYSIS
Syntax analysis is the second phase of the compiler. It gets the input from the tokens and generates a syntax tree or parse tree.
THE ROLE OFPARSER
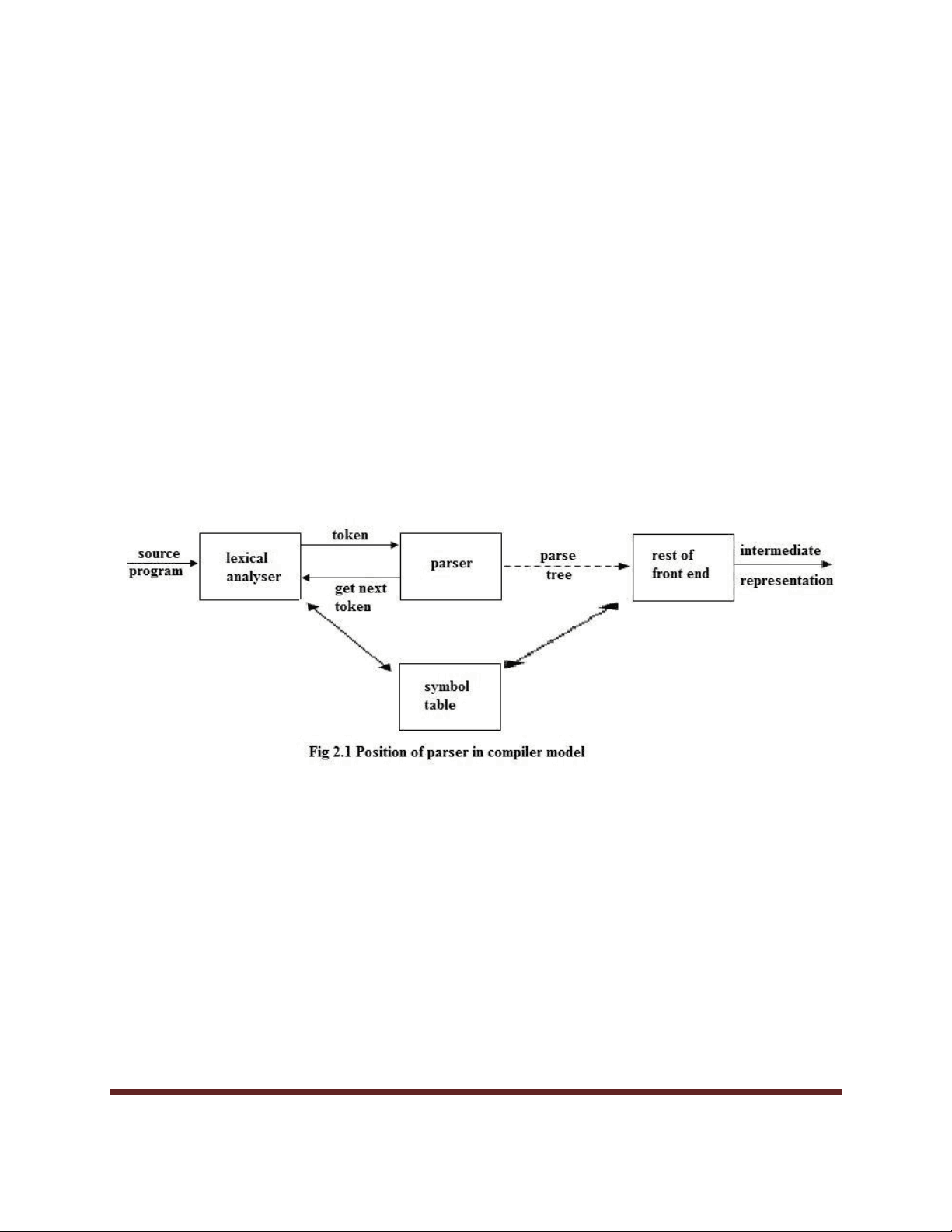
The parser or syntactic analyzer obtains a string of tokens from the lexical analyzer and verifies that the string can be generated by the grammar for the source language. It reports any syntax errors in the program. It also recovers from commonly occurring errors so that it can continue processing its input.
Functions of the parser :
It verifies the structure generated by the tokens based on the grammar. It constructs the parse tree. It reports the errors. It performs error recovery.
Issues :
Parser cannot detect errors such as:
Variable re-declaration Variable initialization before use. Data type mismatch for an operation.
The above issues are handled by Semantic Analysis phase.
Syntax error handling :
Programs can contain errors at many different levels. For example :
Lexical, such as misspelling a keyword. Syntactic, such as an arithmetic expression with unbalanced parentheses. Semantic, such as an operator applied to an incompatible operand. Logical, such as an infinitely recursive call.
Functionsof error handler :
It should report the presence of errors clearly and accurately. It should recover from each error quickly enough to be able to detect subsequent errors. It should not significantly slow down the processing of correct programs.
Error recovery strategies: The different strategies that a parse uses to recover from a syntactic error are: Panic mode Phrase level Error productions Global correction
Panic mode: When a parser encounters an error anywhere in the statement, it ignores the rest of the statement by not processing input from erroneous input to delimiter, such as semi-colon.
This is the easiest way of error-recovery and also, it prevents the parser from developing infinite loops.
Statement mode: When a parser encounters an error, it tries to take corrective measures so that the rest of inputs of statement allow the parser to parse ahead.
S
Now we consider string “aaaaaaa” to derive
S aS aaS aaaS aaaaS aaaaaS aaaaaaS aaaaaaaS
Example 2:
Let L (G), S aSb | ab To find aaabbb Solution: S aSb aaSbb aaaSbbb aaabbb
Example 3: Find aab by S AB A aaA A B Bb B Solution: S AB aaAB aa B aaB aaBb aa b aab Example 4:
Let L (G), S 0S1 | 01 To find 000111 Solution: S 0S 00S 000111 Example 5: Let, G be the grammar S aB | bA A a | aS | bAA B b | bs | aBB For the string baaabbabba. Find LMD, RMD and Parse tree Solution:
Example 6:
PARSING
Syntax analyzers follow production rules defined by means of context-free grammar. The way the production rules are implemented (derivation) divides parsing into two types : top-down parsing and bottom-up parsing.
Top-down Parsing: When the parser starts constructing the parse tree from the start symbol and then tries to transform the start symbol to the input, it is called top-down parsing. Recursive descent parsing : It is a common form of top-down parsing. It is called recursive as it uses recursive procedures to process the input. Recursive descent parsing suffers from backtracking. Backtracking : It means, if one derivation of a production fails, the syntax analyzer restarts the process using different rules of same production. This technique may process the input string more than once to determine the right production.
Bottom-up Parsing: As the name suggests, bottom-up parsing starts with the input symbols and tries to construct the parse tree up to the start symbol.
Example: Input string : a + b * c Production rules:
S → E
E → E + T
E → E * T
E → T
T → id
Let us start bottom-up parsing
a + b * c
Read the input and check if any production matches with the input:
a + b * c
T + b * c E + b * c
E + T * c E * c
E * T
E S
We have learnt in the last chapter that the top-down parsing technique parses the input, and starts constructing a parse tree from the root node gradually moving down to the leaf nodes.
The types of top-down parsing are depicted below:
Recursive Descent Parsing:
Predictive Parser: Predictive parser is a recursive descent parser, which has the capability to predict which production is to be used to replace the input string.
The predictive parser does not suffer from backtracking.
To accomplish its tasks, the predictive parser uses a look-ahead pointer, which points to the next input symbols.
To make the parser back-tracking free, the predictive parser puts some constraints on the grammar and accepts only a class of grammar known as LL(k) grammar.
Predictive parsing uses a stack and a parsing table to parse the input and generate a parse tree.
Both the stack and the input contains an end symbol $ to denote that the stack is empty and the input is consumed.
The parser refers to the parsing table to take any decision on the input and stack element combination.
In recursive descent parsing, the parser may have more than one production to choose from for a single instance of input, whereas in predictive parser, each step has at most one production to choose.
There might be instances where there is no production matching the input string, making the parsing procedure to fail.
Initial State : $S on stack (with S being start symbol)
ω$ in the input buffer
SET ip to point the first symbol of ω$.
repeat
let X be the top stack symbol and a the symbol pointed by ip.
if X∈ Vt or $ if X = a POP X and advance ip. else error() endif
else /* X is non-terminal / if M[X,a] = X → Y1, Y2,... Yk POP X PUSH Yk, Yk- 1 ,... Y1 / Y1 on top */ Output the production X → Y1, Y2,... Yk else error() endif endif
until X = $ /* empty stack */
A grammar G is LL(1) if A → α | β are two distinct productions of G:
for no terminal, both α and β derive strings beginning with a.
at most one of α and β can derive empty string.
if β → t, then α does not derive any string beginning with a terminal in FOLLOW(A).
Bottom-up parsing starts from the leaf nodes of a tree and works in upward direction till it reaches the root node.
Here, we start from a sentence and then apply production rules in reverse manner in order to reach the start symbol. The image given below depicts the bottom-up parsers available.
Shift-Reduce Parsing:
Shift-reduce parsing uses two unique steps for bottom-up parsing.
These steps are known as shift-step and reduce-step.
Shift step : The shift step refers to the advancement of the input pointer to the next input symbol, which is called the shifted symbol. This symbol is pushed onto the stack. The shifted symbol is treated as a single node of the parse tree.
Reduce step : When the parser finds a complete grammar rule (RHS) and replaces it to (LHS), it is known as reduce-step. This occurs when the top of the stack contains a handle. To reduce, a POP function is performed on the stack which pops off the handle and replaces it with LHS non-terminal symbol.
LR Parsing Algorithm:
Here we describe a skeleton algorithm of an LR parser:
token = next_token()
repeat forever
s = top of stack
if action[s, token] = “shift si” then PUSH token PUSH si token = next_token()
else if action[s, token] = “reduce A::= β“ then POP 2 * |β| symbols s = top of stack PUSH A PUSH goto[s,A]
else if action[s, token] = “accept” then return
else error()
LL vs. LR
LL LR
Does a leftmost derivation. Does a rightmost derivation in reverse.
Starts with the root nonterminal on the stack.
Ends with the root nonterminal on the stack.
Ends when the stack is empty. Starts with an empty stack.
Uses the stack for designating what is still to be expected.
Uses the stack for designating what is already seen.
Builds the parse tree top-down. Builds the parse tree bottom-up.
Continuously pops a nonterminal off the stack, and pushes the corresponding right hand side.
Tries to recognize a right hand side on the stack, pops it, and pushes the corresponding nonterminal.
Expands the non-terminals. Reduces the non-terminals.
Reads the terminals when it pops one off the stack.
Reads the terminals while it pushes them on the stack.
Pre-order traversal of the parse tree. Post-order traversal of the parse tree.