Download Pipelining and Vector Processing - Computer Architecture - Lecture Slides and more Slides Computer Architecture and Organization in PDF only on Docsity!
PIPELINING AND VECTOR PROCESSING • • • • Arithmetic PipelineParallel ProcessingPipeliningInstruction Pipeline
• • • Array ProcessorsRISC PipelineVector Processing Docsity.com
Levels of Parallel Processing - Job or Program levelPARALLEL PROCESSING
Execution of process to achieve faster- Task or Procedure level- Inter-Instruction level- Intra-Instruction level Concurrent Events Computational Speed in the computing
Parallel Processing
COMPUTER ARCHITECTURES FOR PARALLEL Von-Neuman based PROCESSING
Dataflow Reduction^ SISDMISD^ SIMDMIMD^ Superscalar processors^ Superpipelined processors^ VLIW^ Nonexistence^ Array processors^ Systolic arrays Associative processors Shared-memory multiprocessors Message-passing multicomputers Bus based Crossbar switch based Multistage IN based Hypercube Mesh Reconfigurable
Parallel Processing
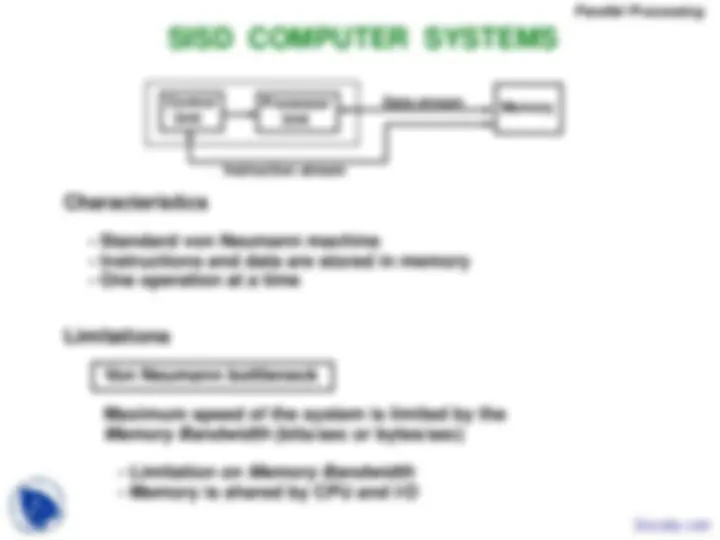
Characteristics - Standard von Neumann machine - Instructions and data are stored in memory - One operation at a time^ ControlSISD COMPUTER SYSTEMS^ Unit^ Instruction stream^ ProcessorUnit^ Data stream Memory
Limitations Von Neumann bottleneck Maximum speed of the system is limited by the Memory Bandwidth - Limitation on - Memory is shared by CPU and I/O Memory Bandwidth (bits/sec or bytes/sec)
Parallel Processing
M M M Instruction stream • • • MISD COMPUTER SYSTEMSCUCUCU • • • PPP Memory Data stream
Characteristics - There is no computer at present that can beclassified as MISD
Parallel Processing
SIMD COMPUTER SYSTEMS P Alignment networkP Control Unit Memory • • • P
Characteristics - Only one copy of the program exists- A single controller executes one instruction at a time^ Data bus^ M^ M^ Data stream • • •^ Instruction streamM^ Processor units^ Memory modules
Parallel Processing
CharacteristicsMIMD COMPUTER SYSTEMS^ P^ M^ P^ Interconnection Network^ Shared MemoryM^ • • • P^ M
Types of MIMD computer systems^ - Multiple processing units- Execution of multiple instructions on multiple data - Shared memory multiprocessors - Message-passing multicomputers
Parallel Processing
CharacteristicsSHARED MEMORY MULTIPROCESSORS All processors have equally direct access toone large memory address space
Example systems Limitations Bus and cache-based systemsMultistage IN-based systemsCrossbar switch-based systems Memory access latencyHot spot problemP^ M^ - Sequent Balance, Encore Multimax- Ultracomputer, Butterfly, RP3, HEP- C.mmp, Alliant FX/8^ Interconnection Network(IN)MP^ • • •^ • • • MP^ Buses,Multistage IN,Crossbar Switch
Parallel Processing
PIPELINING
R1 R3 R5 AR1 * R2, R4R3 + R4i, R2 Bi Ci AddLoad Ai and Bi Multiply and load Ci
A technique of decomposing a sequential processinto suboperations, with each subprocess beingexecuted in a partial dedicated segment thatoperates concurrently with all other segments. A R1 Ai i* B Multiplieri R3 + C i R2for i = 1, 2, 3, ... , 7R
Adder R5^ Memory Segment 1^ Bi^ Ci^ Pipelining Segment 2 Segment 3 Docsity.com
OPERATIONS IN EACH PIPELINE STAGE Number ClockPulse 123456789 Segment 1R1A2A3A4A5A6A7A1 R2B2B3B4B5B6B7B1 A7 * B7A1 * B1A2 * B2A3 * B3A4 * B4A5 * B5A6 * B6R3Segment 2 C1C2C3C4C5C6C7R4 A1 * B1 + C1A2 * B2 + C2A3 * B3 + C3A4 * B4 + C4A5 * B5 + C5Segment 3A6 * B6 + C6A7 * B7 + C7R5^ Pipelining
Conventional Machine (Non-Pipelined) Pipelined Machine (k stages)^ n: t t tt tnp 11 k: :::^ = n * t Number of tasks to be performedClock cycle (time to complete each suboperation)Time required to complete the n tasksClock cycleTime required to complete the n tasksn PIPELINE SPEEDUP
Speedup^ tSSlim nkkk^ : = (k + n - 1) * t= nt SpeedupSkn / (k + n - 1)t= t tnp p ( = k, if tp n = k * tp )
Pipelining
PIPELINE AND MULTIPLE FUNCTION UNITS
Multiple Functional Units^ IP^ i 1 I^ Pi+1 2 I^ P^ i+2 3 I^ P^ i+3 4
Example- 4-stage pipeline- subopertion in each stage; t- 100 tasks to be executed - 1 task in non-pipelined system; 204 = 80nS Pipelined SystemNon-Pipelined SystemSpeedupnktS (k + n - 1)tp = 100 * 80 = 8000nSp = (4 + 99) * 20 = 2060nSp = 20nS
4-Stage Pipeline is basically identical to the system with 4 identical function unitsk^ = 8000 / 2060 = 3.
Pipelining
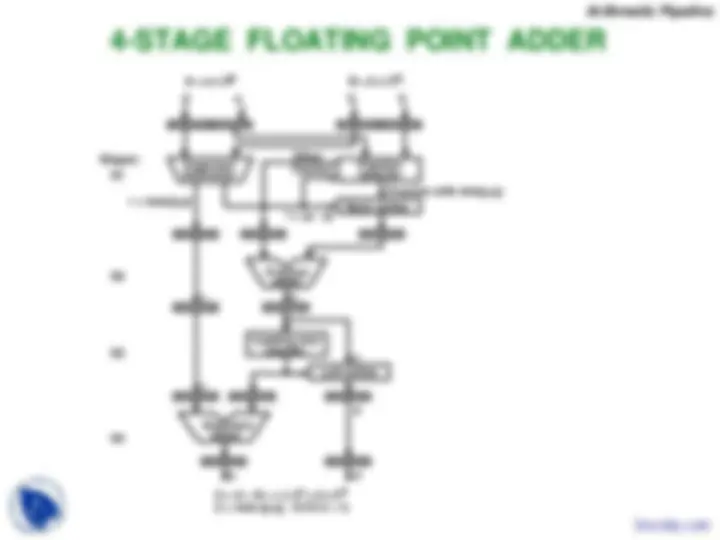
4-STAGE FLOATING POINT ADDER r = max(p,q) subtractor p Exponent A = a x 2 pa Fraction adder t = |p - q| fraction Other Right shifterqB = b x 2 Fraction selector Fraction with min(p,q)qb
Stages: S1 S2 S3 S4 r r Exponent (^) adder C = A + B = c x 2 = d x 2 (r = max (p,q), 0.5 s Leading zero countercr (^) d < 1) Left shifters cd d Arithmetic Pipeline
Six Phases* in an Instruction Cycle [1] Fetch an instruction from memory [2] Decode the instruction [3] Calculate the effective address of the operand [4] Fetch the operands from memory [5] Execute the operation [6] Store the result in the proper place * Some instructions skip some phases * Effective address calculation can be done in the part of the decoding phaseINSTRUCTION CYCLE
* Storage of the operation result into a register ==> 4-Stage Pipeline [1] FI: [2] DA: Decode the instruction and calculate [3] FO: Fetch the operand [4] EX: Execute the operation is done automatically in the execution phase Fetch an instruction from memory the effective address of the operand
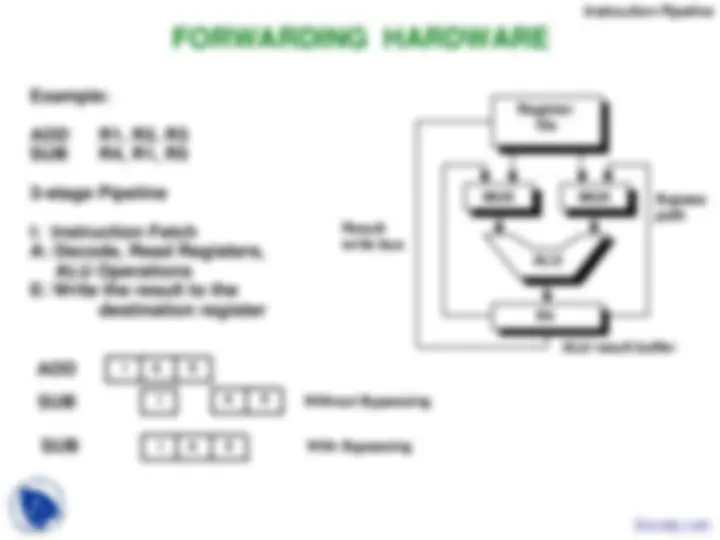
Instruction Pipeline