


3-Software Design Basics in
Embedded Systems
1
Optimizing the design of General
Purpose processors
Docsity.com















Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Community
Ask the community for help and clear up your study doubts
Discover the best universities in your country according to Docsity users
Free resources
Download our free guides on studying techniques, anxiety management strategies, and thesis advice from Docsity tutors
An overview of software design basics for embedded systems, focusing on optimizing instruction execution in general purpose processors. Topics include pipelining, superscalar architectures, cache memory, and microprocessor selection. Students and professionals in computer engineering, electronics, and related fields will find this information useful for understanding the fundamentals of software design for embedded systems.
Typology: Slides
1 / 25

This page cannot be seen from the preview
Don't miss anything!
Fetch-instr.
Decode
Fetch ops.
Execute
Store res.
Wash
Dry
Time
Non-pipelined Pipelined
Time
Time
Pipelined
pipelined instruction execution
non-pipelined dish cleaning pipelined dish cleaning
Instruction 1
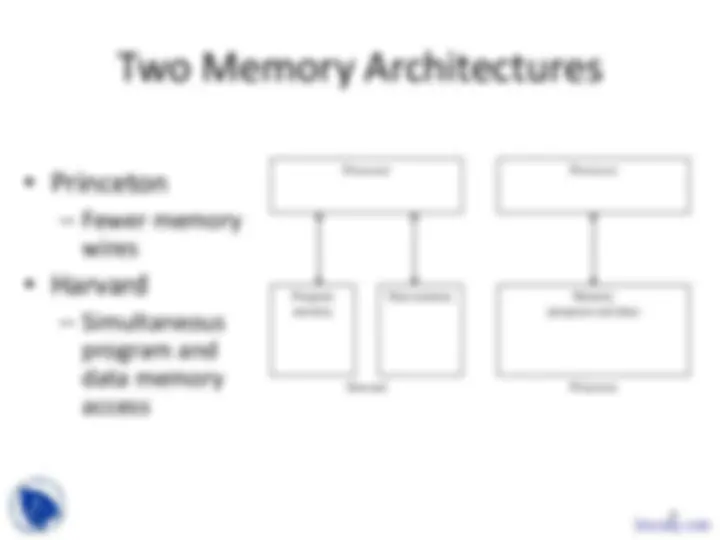
Processor
Program memory
Data memory
Processor
Memory (program and data)
Harvard Princeton
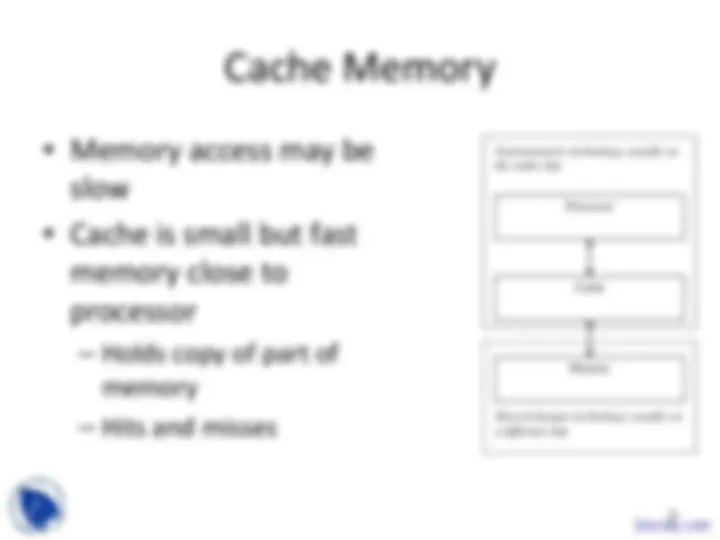
Processor
Memory
Cache
Fast/expensive technology, usually on the same chip
Slower/cheaper technology, usually on a different chip
opcode operand1 operand
opcode operand1 operand
opcode operand1 operand
opcode operand1 operand
Instruction 1
Instruction 2
Instruction 3
Instruction 4
opcode operands
MOV Rn, direct
MOV @Rn, Rm
ADD Rn, Rm
0000 Rn direct
0010 Rn
0100 Rn Rm
Rn = M(direct)
Rn = Rn + Rm
SUB Rn, Rm 0101 Rm Rn = Rn - Rm
MOV Rn, #immed. 0011 Rn immediate Rn = immediate
Assembly instruct. First byte Second byte Operation
JZ Rn, relative 0110 Rn relative PC = PC+ relative (only if Rn is 0)
Rn
MOV direct, Rn 0001 Rn direct M(direct) = Rn
Rm (^) M(Rn) = Rm
int total = 0; for (int i=10; i!=0; i--) total += i; // next instructions...
C program
MOV R0, #0; // total = 0 MOV R1, #10; // i = 10
JZ R1, Next; // Done if i= ADD R0, R1; // total += i
MOV R2, #1; // constant 1
JZ R3, Loop; // Jump always
Loop:
Next: // next instructions...
SUB R1, R2; // i--
Equivalent assembly program
MOV R3, #0; // constant 0
delete a few instructions
designer would normally do (if desire
a complex big scale GPP)
Declarations: bit PC[16], IR[16]; bit M[64k][16], RF[16][16];
Aliases: op IR[15..12] rn IR[11..8] rm IR[7..4]
dir IR[7..0] imm IR[7..0] rel IR[7..0]
Reset
Fetch
Decode
IR=M[PC]; PC=PC+
Mov1 RF[rn] = M[dir]
Mov
Mov
Mov
Add
Sub
Jz 0110
0101
0100
0011
0010
0001
op = 0000
M[dir] = RF[rn]
M[rn] = RF[rm]
RF[rn]= imm
RF[rn] =RF[rn]+RF[rm]
RF[rn] = RF[rn]-RF[rm]
PC=(RF[rn]=0) ?rel :PC
to Fetch
to Fetch
to Fetch
to Fetch
to Fetch
to Fetch
to Fetch
PC=0;
from states below
FSMD
Datapath
PC IR
Controller (Next-state and control logic; state register)
Memory
RF (16)
RFwa RFwe RFr1a RFr1e RFr2a RFr2e
RFr1 RFr
RFw
ALU
ALUs
2x1 mux
ALUz
RFs
PCld PCinc PCclr
Ms (^) 3x1 mux Mre Mwe
To all input control signals
From all output control signals
Control unit
16 Irld
2
1
0
A D
1
0