Download Natural Language Processing (NLP) module 4 and more Lecture notes Natural Language Processing (NLP) in PDF only on Docsity!
NATURAL LANGUAGE
PROCESSING (21AI62)
Dr. Pushpalatha K
Professor Sahyadri College of Engineering & Management
Information Retrieval
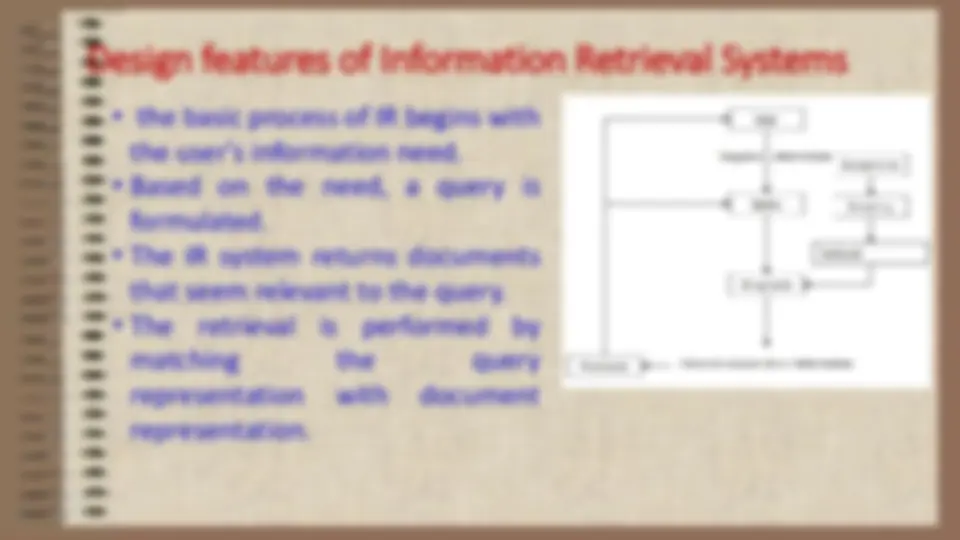
- Information retrieval (IR) deals with the organization, storage, retrieval, and evaluation of information relevant to a user's query.
- A user in need of information formulates a request in the form of a query written in a natural language.
- The retrieval system responds by retrieving the document that seems relevant to the query.
- The actual text of the document is not used in the retrieval process.
- Instead, documents in a collection are frequently represented through a
set of index terms or keywords.
- The process of transforming document text to some representation of it is
known as indexing.
▪ There are different types of index structures.
▪ inverted index is commonly used data structure by the IR system.
▪ An inverted index is simply a list of keywords, with each keyword carrying
pointers to the documents containing that keyword.
▪ The computational cost involved in adopting a full text logical view is high.
▪ Hence, the set of representative keywords are reduced.
▪ The two most commonly used text operations are stop word elimination
and stemming.
▪ Stop word elimination removes grammatical or functional words, while
stemming reduces words to their common grammatical roots.
▪ Zipf's law can be applied to reduce the size of index set based on the
relevancy of the index term.
Indexing
- In a small collection of documents, an IR system can access a document to decide its relevance to a query.
- But a large collection of raw documents is usually transformed into an easily accessible representation which is known as indexing.
- Most indexing techniques involve identifying good document descriptors, such as keywords or terms, which describe the information content of documents. ▪ A good descriptor is one that helps describe the content of the document and discriminate it from other documents in the collection. ▪ Eg: The stemmed representation of the text, Design features of information retrieval systems, is {design, feature, inform, retrieve, system} ▪ One of the problems associated with stemming is that it may throw away useful distinctions. - In some cases, it may be useful to help conflate similar terms, resulting in increased recall. - Recall and precision are the two most commonly used measures of the effectiveness of an information retrieval system, and are explained in detail later in this chapter.
- Zipf's law on large corpuses suggest that human languages contain a small number of words that occur with high frequency and a large number of words that occur with low frequency.
- The high frequency words being common, have less discriminating power, and thus, are not useful for indexing.
- Low frequency words are less likely to be included in the query, and are also not useful for indexing.
- As there are a large number of rare (low frequency) words, dropping them considerably reduces the size of a list of index terms.
- The remaining medium frequency words are content-bearing terms and can be used for indexing. ▪ This can be implemented by defining thresholds for high and low frequency, and dropping words that have frequencies above or below these thresholds. ▪ Stop word elimination can be thought of as an implementation of Zipf's law, where high frequency terms are dropped from a set of index terms.
Information Retrieval Models
- IR models can be classified as ▪ Classical models of IR. ▪ Non-classical models of IR ▪ Alternative models of IR
- The three classical IR models-Boolean, vector, and probabilistic. ▪ These are based on mathematical knowledge that is easily recognized and well understood. ▪ These models are simple, efficient, and easy to implement.
Boolean Model
- Introduced in the 50 s, the Boolean model is the oldest of the three
classical models.
- It is based on Boolean logic and classical set theory.
- In this model, documents are represented as a set of keywords,
usually stored in an inverted file.
▪ An inverted file is a list of keywords and identifiers of the documents in which they occur.
- Users are required to express their queries as a Boolean expression
consisting of keywords connected with Boolean logical operators
(AND, OR, NOT).
- Retrieval is performed based on whether or not document contains
the query terms.
- Let T={t 1 ,t 2 ,..…,t m } be the set of all such index terms.
▪ A document is any subset of T.
- Let D={D 1 ,D 2 ,..…,D m } be the set of all documents.
- A query is a Boolean expression Q in normal form
▪ Q= ∧( ∨ Θ
i
i
∈{t
i
, ¬t
i
- The retrieval is performed in two steps:
- The set R i of documents are obtained that contain or do not contain the term t i .
▪ R
i
={d
j
i
∈ d
j
i
∈{t
i
, ∈ t
i
- Where ¬t i ∈ d j means ¬t i ∉ d j
- The set of operations are used to retrieve documents in response to Q : ∩R i
- Let the query Q be Q= information ∧ retrieval.
- First, the sets R 1 and R 2 of documents are retrieved in response to Q, ▪ where R 1 = {d j | information ∈ d j } = {d 1 , d 2 } ▪ R 2 = {d j | retrieval∈ d j } = {d 1 , d 3 } ▪ The documents retrieved in response to query Q - {d j | d j ∈ R 1 ∩R 2 } = {d 1 } - This results in the retrieval of the original document D, that has the representation d 1. ▪ If more than one document have the same representation, every such document is retrieved. ▪ With an inverted index, takes an intersection of the list of the documents associated with the keywords information and retrieval.
Drawbacks of Boolean Model
- The model is not able to retrieve documents that are only partly relevant to user query; all information is 'to be or not to be'.
- A Boolean system is not able to rank the returned list of documents. ▪ It distinguishes between presence and absence of keywords but fails to assign relevance and importance to keywords in a document.
- Users seldom formulate their query in the pure Boolean expression that this model requires.
- if P(R/d) is the probability of relevance of a document d, for query q, and P(I/d) is the probability of irrelevance, then the set of documents retrieved in response to the query q is as follows. ▪S={d j |P(R/ d j ) ≥ P(I/ d j )} P(R/ d j ) ≥ α
- The probabilistic model can produce results that partly match the user query. ,
- Determination of a threshold value is the main drawback of probabilistic model IR.
Vector Space Model
- The vector space model is one of the most well-studied retrieval models.
▪ Important contribution to its development was made by Luhn ( 1959 ),
Salton ( 1968 ), Salton and McGill ( 1983 ), and van Rijsbergen ( 1977 ).
- The vector space model represents documents and queries as vectors of
features representing terms that occur within them.
- Each document is characterized by a Boolean or numerical vector.
- These vectors are represented in a multi-dimensional space, in which each
dimension corresponds to a distinct term in the corpus of documents.
▪ In its simplest form, each feature takes a value of either zero or one,
indicating the absence or presence of that term in a document or query.
▪ More generally, features are assigned numerical values that are usually a
function of the frequency of terms.
- Ranking algorithms compute the similarity between document and query
vectors, to yield a retrieval score to each document.
- This score is used to produce a ranked list of retrieved documents.
- D 1 = Information retrieval is concerned with the organization, storage,
retrieval, and evaluation of information relevant to user's query.
- D 2 = A user having an information needs to formulate a request in the
form of query written in natural language.
- D 3 = The retrieval system responds by retrieving the document that seems
relevant to the query.
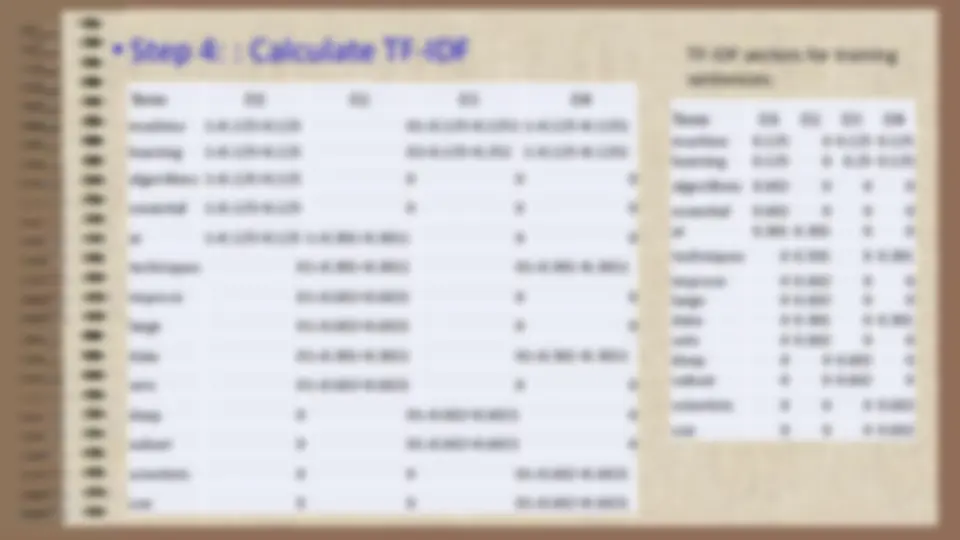
- T= {information, retrieval, query}.
- The associated vector for above documents is ( 2 , 2 , 1 )
- Term document frequency matrix is 2 1 0
- To reduce the importance of the length of document vectors, document vectors can be normalized.
- Normalization changes all vectors to a standard length. ▪ Convert document vectors to unit length by dividing each dimension by the overall length of the vector. ▪ Normalized the term-document matrix:
- 67 0. 71 0
- 67 0 0. 71
- 33 0. 71 0. 71 ▪ Elements of each column are divided by the length of the column vector given by σ 𝑖 𝑤 2 𝑖𝑗 .