


Database Management Systems Design
Docsity.com








Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Community
Ask the community for help and clear up your study doubts
Discover the best universities in your country according to Docsity users
Free resources
Download our free guides on studying techniques, anxiety management strategies, and thesis advice from Docsity tutors
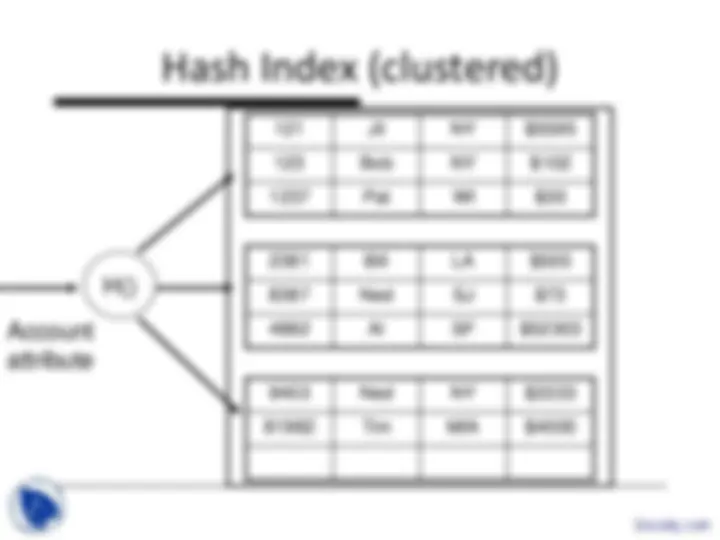
An overview of index files in database management systems (dbms), discussing their forms, clustered vs unclustered indexes, and hash-based indexing. It covers the concepts of index entries, data entries, and search keys, as well as issues related to primary and secondary indexes.
Typology: Slides
1 / 14

This page cannot be seen from the preview
Don't miss anything!
121 Jil NY $ 123 Bob NY $ 1237 Pat WI $ 2381 Bill LA $ 4882 Al SF $ 8387 Ned SJ $ 9403 Ned NY $ 81982 Tim MIA $
121 Jil NY $ 123 Bob NY $ 1237 Pat WI $ 2381 Bill LA $ 8387 Ned SJ $ 4882 Al SF $ 9403 Ned NY $ 81982 Tim MIA $
121 Jil NY $ 123 Bob NY $ 1237 Pat WI $ 2381 Bill LA $ 8387 Ned SJ $ 4882 Al SF $ 9403 Ned NY $ 81982 Tim MIA $
Docsity.com