


Using The CUDA Programming
Model
1
Leveraging GPUs for Application Acceleration
Docsity.com



























Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Community
Ask the community for help and clear up your study doubts
Discover the best universities in your country according to Docsity users
Free resources
Download our free guides on studying techniques, anxiety management strategies, and thesis advice from Docsity tutors
An overview of the cuda programming model, its benefits, and the specifications of nvidia gpus such as tesla c2050 and s2050. It also compares the performance of x86 and s2050 and discusses the concepts of grids, blocks, threads, and kernels in cuda. The document aims to help readers understand how to leverage gpus for application acceleration.
Typology: Slides
1 / 40

This page cannot be seen from the preview
Don't miss anything!
1
Leveraging GPUs for Application Acceleration
Modern Architecture (Intel)
FIGURE A.2.2 Contemporary PCs with Intel and AMD CPUs. See Chapter 6 for an explanation of the components and interconnects in this figure. Copyright © 2009 Elsevier
8
Figure 1.1. Enlarging Performance Gap betw een GPUs and CPUs.
Multi-core CPU
Many-core GPU
Courtesy: John Owens
(looks like any other server node)
(at most 16 GB/sec)
11
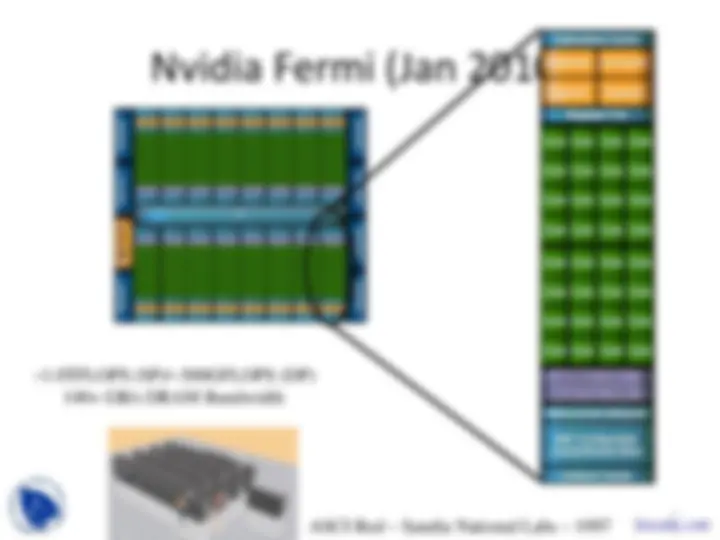
Dual socket, AMD 2.3 GHz 12-core
NVIDIA Tesla S
DP GFLOPs/Watt ~0.5 GFLOPs/Watt ~1.6 GFLOPs/Watt (~3x) SP GFLOPS/Watt ~1 GFLOPs/Watt ~3.2 GFLOPs/Watt (~3x) DP GFLOPs/sq ft ~590 GFLOPs/sq ft ~2750 GFLOPs/sq ft (4.7x) SP GFLOPs/sq ft ~1180 GFLOPs/sq ft ~5500 GFLOPs/sq ft (4.7x) Racks per PFLOP DP 142 racks/PFLOP DP 32 racks/PFLOP DP (23%) Racks per PFLOP SP 71 racks/PFLOP SP 16 racks/PFLOP SP (23%)
OU’s Sooner is 34.5 TFLOPs DP, which is just over 1 rack of S2050.
13
Input Registers Fragment Program
Output Registers
Constants
Texture
Temp Registers
per Shader^ per thread per Context
FB Memory
14
GPU
16
Serial Code (host)
... ...
Parallel Kernel (device) KernelA<<< nBlk, nTid >>>(args);
Serial Code (host)
Parallel Kernel (device) KernelB<<< nBlk, nTid >>>(args);
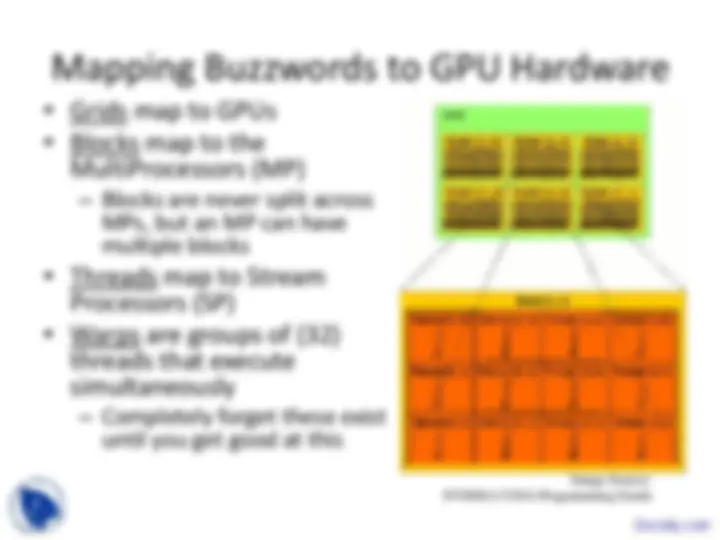
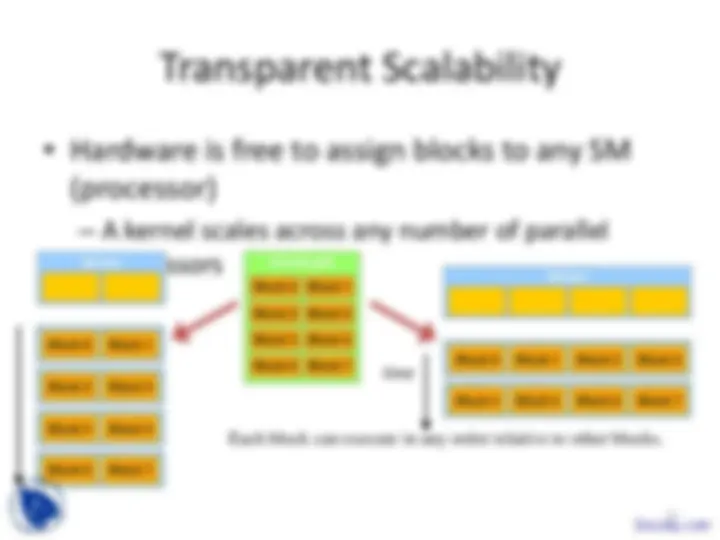
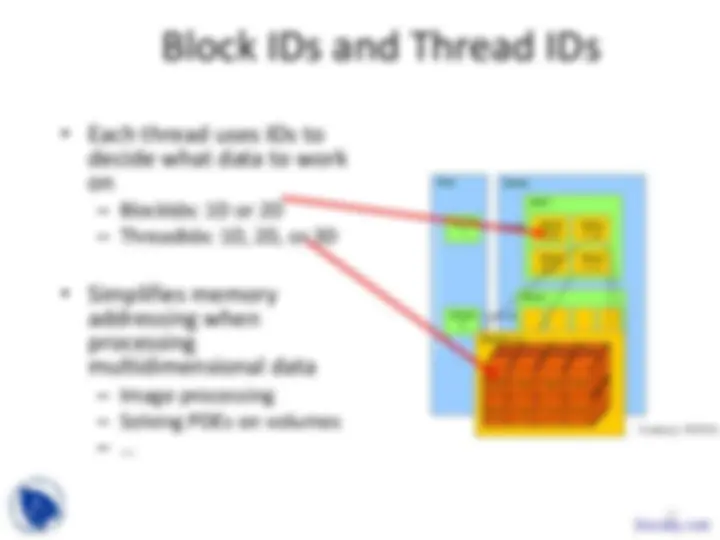
a kernel with a given index.
threads in OpenMP
CUDA?
19
0 1 2 3 4 5 6 7
… float x = input[threadID]; float y = func(x); output[threadID] = y; …
threadID