

Intro. to machine learning (CSI 5325) Lecture 3: concept learning
Intro. to machine learning (CSI 5325)
Lecture 3: concept learning
Greg Hamerly
Fall 2008
Some content from Tom Mitchell.
1 / 25














Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Community
Ask the community for help and clear up your study doubts
Discover the best universities in your country according to Docsity users
Free resources
Download our free guides on studying techniques, anxiety management strategies, and thesis advice from Docsity tutors
A part of the lecture notes for the 'intro to machine learning' (csi 5325) course at carnegie mellon university, focusing on concept learning and the candidate elimination algorithm. It covers the definition of concept learning, the candidate elimination algorithm, and its limitations, as well as the importance of inductive bias and the need for picking new examples.
Typology: Study notes
1 / 25

This page cannot be seen from the preview
Don't miss anything!
Greg Hamerly
Fall 2008
Some content from Tom Mitchell.
Outline
1 Concept learning
2 Candidate elimination algorithm (recap)
3 Picking new examples
4 The need for inductive bias
5 Where we are going
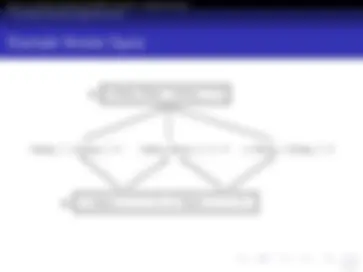
Candidate elimination algorithm (recap)
S:
<Sunny, ?, ?, Strong, ?, ?> <Sunny, Warm, ?, ?, ?, ?>
{ <Sunny, Warm, ?, Strong, ?, ?> }
G: { <Sunny, ?, ?, ?, ?, ?>, ^ }
Candidate elimination algorithm (recap)
The General boundary, G, of version space VSH,D is the set of its maximally general members
The Specific boundary, S, of version space VSH,D is the set of its maximally specific members
Every member of the version space lies between these boundaries
VSH,D = {h ∈ H|(∃s ∈ S)(∃g ∈ G )(g ≥ h ≥ s)}
where x ≥ y means x is more general or equal to y
Candidate elimination algorithm (recap)
For a positive example d: Remove from G any hypothesis inconsistent with d
For each hypothesis s in S that is not consistent with d Remove s from S Add to S all minimal generalizations h of s such that h is consistent with d, and some member of G is more general than h Remove from S any hypothesis that is more general than another hypothesis in S
Candidate elimination algorithm (recap)
For a negative example d: Remove from S any hypothesis inconsistent with d
For each hypothesis g in G that is not consistent with d Remove g from G Add to G all minimal specializations h of g such that h is consistent with d, and some member of S is more specific than h Remove from G any hypothesis that is less general than another hypothesis in G
Candidate elimination algorithm (recap)
What would happen to the candidate elimination algorithm if it encountered an incorrectly-labeled example?
The algorithm removes every hypothesis that is inconsistent with some training example. Therefore, the true concept will be removed!
What does this show about our assumptions that the data has no noise? the hypothesis space contains the correct hypothesis?
Picking new examples
Does the order of the training data matter? in correctness of the algorithm? in efficiency of the algorithm?
Picking new examples
S:
<Sunny, ?, ?, Strong, ?, ?> <Sunny, Warm, ?, ?, ?, ?>
{ <Sunny, Warm, ?, Strong, ?, ?> }
G: { <Sunny, ?, ?, ?, ?, ?>, ^ }
〈Sunny Warm Normal Strong Cool Change〉 〈Rainy Cool Normal Light Warm Same〉 〈Sunny Warm Normal Light Warm Same〉
The need for inductive bias
S : 〈Sunny Warm Normal?? ?〉
Why believe we can classify the unseen
〈Sunny Warm Normal Strong Warm Same〉
The need for inductive bias
Idea: Choose H that expresses every teachable concept (i.e., H is the power set of X ) Consider H′^ = disjunctions, conjunctions, negations over previous H. E.g.,
〈Sunny Warm Normal?? ?〉 ∨ ¬〈????? Change〉
What are S, G in this case? S ← G ←
The need for inductive bias
Consider concept learning algorithm L instances X , target concept c training examples Dc = {〈x, c(x)〉} let L(xi , Dc ) denote the classification assigned to the instance xi by L after training on data Dc.
Definition: The inductive bias of L is any minimal set of assertions B such that for any target concept c and corresponding training examples Dc
(∀xi ∈ X )[(B ∧ Dc ∧ xi ) ` L(xi , Dc )]
where A ` B means A logically entails B
The need for inductive bias
1 Rote learner: Store examples, Classify x iff it matches previously observed example. 2 Version space candidate elimination algorithm 3 Find-S
The need for inductive bias
What is the inductive bias of the TTT player you’re writing?