


Econometric Analysis of Panel Data
21. Bayesian Econometric Models
for Panel Data
Docsity.com
















































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Community
Ask the community for help and clear up your study doubts
Discover the best universities in your country according to Docsity users
Free resources
Download our free guides on studying techniques, anxiety management strategies, and thesis advice from Docsity tutors
Bayesian Econometric Models, Panel Data, Philosophical Underpinning, Objectivity and Subjectivity, Paradigms, Applications of the Paradigm, Likelihoods, Likelihood Principle are points which describes this lecture importance in Econometric Analysis of Panel Data course.
Typology: Slides
1 / 56

This page cannot be seen from the preview
Don't miss anything!
21. Bayesian Econometric Models
for Panel Data
A Philosophical Underpinning
Paradigms
Evidence consistent with theory? Theory stands and waits for
more evidence to be gathered
Evidence conflicts with theory? Theory falls
Applications of the Paradigm
The Likelihood Principle
Application:
th
7 13
7 13
The Bayesian Estimator
Priors and Posteriors
Conjugate Prior
s N s s N s
a 1 b 1
Mathematical device to produce a tractable posterior
This is a typical application
N (^) (N 1) L( ;N,s)= (1 ) (1 )
s (s 1) (N s 1)
(a+b) Use a , p( )= (1 )
(a) (b)
Po
− −
− −
Γ + θ (^) θ − θ = θ − θ
Γ^ +^ Γ^ −^ +
Γ θ θ − θ Γ Γ
conjugate beta prior
s N s a 1 b 1
1 s N s a 1 b 1
0
s a 1 N s b 1
1 s a 1 N s b
0
(N 2) (a+b) (1 ) (1 ) (s 1) (N s 1) (a) (b) sterior (N 2) (a+b) (1 ) (1 ) d (s 1) (N s 1) (a) (b)
(1 )
(1 )
− − −
− − −
− − + −
− − + −
Γ + Γ θ^ − θ^ θ^ − θ Γ^ +^ Γ^ −^ +^ Γ^ Γ = Γ + Γ θ^ − θ^ θ^ − θ^ θ Γ^ +^ Γ^ −^ +^ Γ^ Γ
θ − θ
1
a Beta distribution.
d
s+a Posterior mean = (we used a = b = 1 before)
N+a+b
=
θ
Bayesian Estimators
= ∫
f(data | )p( ) E( | data) d β f(data)
β β β β β
Marginal Posterior for β
2
2 2 / 2 1 / 2
2 1 / 2 2
2 1
After integrating out of the joint posterior:
[ ] ( / 2) [2 ] | | ( 2) ( | , ). [ ( ) ( )]
n-K
Multivariate t with mean and variance matrix [ ( ) ]
2
The Bayesi
v K
d K
ds d K
d f
ds
s n K
σ
π
− −
−
Γ + ′
Γ + ∝
− −
X X
β y X β b X X β b
b X'X
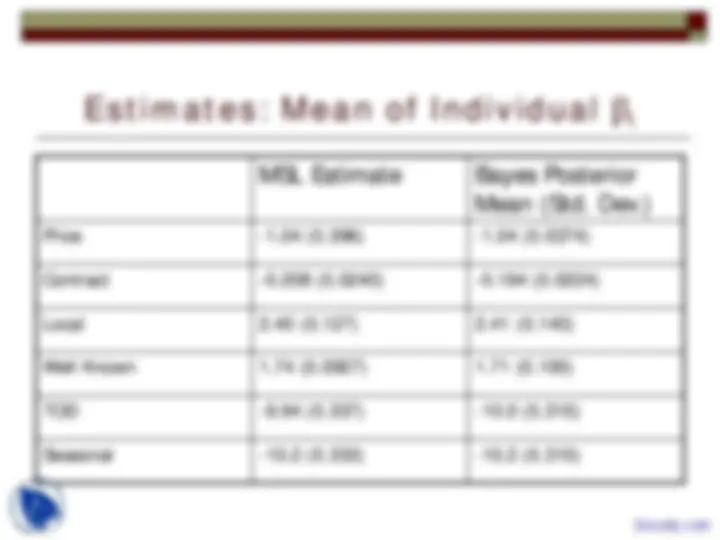
an 'estimator' equals the MLE. Of course; the prior was
noninformative. The only information available is in the likelihood.
Nonlinear Models and Simulation